CouchDB Indexing Benchmark
19/Dec 2016
In the last post, we discussed how CouchDB’s external query server works by examining the raw protocol. In this post, we’re going to take a look at the performance of different query servers.
The code used in this benchmarking is here.
I listed below the method of the benchmark in detail. If you want you can jump to conclusion.
The Setup
The benchmarks are done on my laptop (Intel 6th-gen i7 processor, 8G RAM, SSD) with CouchDB 1.6 in a docker container. Since we’re benchmarking python views as well, we’re going to customize the docker image add python query server to it. Here’s the dockerfile:
FROM couchdb
RUN apt-get update -yqq && apt-get install -y python python-pip
RUN pip install couchdb
Build a new image with that dockerfile, and start a couchdb instance with (assuming you named your image couchdb-python from the last step):
docker run -p 9999:5984 -d -v $(pwd)/data:/usr/local/var/lib/couchdb couchdb-python
Your couchdb instance will be accessible via localhost:9999. By default, the container is started in the admin party mode (everybody is an admin) but since we use it only for the purpose of testing, we won’t bother with setting up username/password.
$ curl http://localhost:9999/
{"couchdb":"Welcome","uuid":"47a7b22e608a73fc2214ed13063923b8","version":"1.6.1","vendor":{"version":"1.6.1","name":"The Apache Software Foundation"}}
Preparing the data
The data we’re working have simple structures. We’ll be generating data of the following form:
{
"metadata": {
"docType": "userscore",
"createdAt": "2016-12-19T19:28:14.000"
},
"username": "barry",
"score": 912
}
We are storing the name of the user along with their score in the document, whatever that is. It’s a contrived example so bear with me :)
To populate a dataset for our benchmarking, let’s use a script:
import string
import sys
import requests
import random
import datetime
from multiprocessing import Pool
DB_URL = 'http://localhost:9999/test'
def random_name():
generate_character = lambda _: random.choice(string.ascii_letters)
return ''.join(map(generate_character, range(6)))
def random_date():
# get a random date from within last year
today = datetime.date.today()
that_day = today - datetime.timedelta(days=random.randint(0, 366))
return datetime.datetime.strftime(that_day, '%Y-%m-%d')
def generate_doc(_):
doc = {
'metadata': {
'docType': 'score',
'createdAt': random_date()
},
'username': random_name(),
'score': random.randint(0, 5000)
}
response = requests.post(DB_URL, json=doc)
response.raise_for_status()
if __name__ == '__main__':
num_of_docs = int(sys.argv[1])
requests.delete(DB_URL) # delete the database if it exists already
response = requests.put(DB_URL) # create the test database
print('Generating {} docs'.format(num_of_docs))
pool = Pool(50)
pool.map(generate_doc, range(num_of_docs))
stats = requests.get('{}/'.format(DB_URL)).json()
print('doc_count: {}'.format(stats['doc_count']))
print('disk_size: {}'.format(stats['disk_size']))
You can seed the database by using: python /path/to/script.py 100000 to create 100k documents. This is likely to take a while:
python generate_data.py 100000
doc_count: 100000
disk_size: 111153301
As you can see, now we have a test database with 100000 documents.
Setup Python Query Server
Python query server needs to be activated. You can either change it in the config file on the container and restart it or change it on the fly with the _config endpoint.
We can take a look at what’s currently configured:
$ curl http://localhost:9999/_config/query_servers
{"javascript":"/usr/local/bin/couchjs /usr/local/share/couchdb/server/main.js","coffeescript":"/usr/local/bin/couchjs /usr/local/share/couchdb/server/main-coffee.js"}
Let’s add python query server there:
curl -XPUT -H"Content-Type: application/json" http://localhost:9999/_config/query_servers/python -d'"/usr/bin/python /usr/local/bin/couchpy"'
and verify that it’s saved:
$ curl http://localhost:9999/_config/query_servers
{"javascript":"/usr/local/bin/couchjs /usr/local/share/couchdb/server/main.js","coffeescript":"/usr/local/bin/couchjs /usr/local/share/couchdb/server/main-coffee.js","python":"/usr/bin/python /usr/local/bin/couchpy"}
Benchmark Javascript views
The view we are going to write is to calculate the total score of all users for a given month. We will have a map function to map each document to ([Year, Month], Score) and a reduce function to sum up all the scores.
Map/Reduce function
The map function written in Javascript:
function(doc) {
if (doc.metadata && doc.metadata.createdAt) {
var parts = doc.metadata.createdAt.split("-"),
year = parts[0],
month = parts[1];
emit([year, month], doc.score);
}
}
and the reduce function:
function(keys, values, rereduce) {
return sum(values);
}
Let’s save it as a design doc _design/scoresByMonthJS:scoresByMonth. You can use either Futon or curl or cdbcli.
To invoke the view, we can send a curl request to http://localhost:9999/test/_design/scoresByMonthJS/_view/scoresByMonth?limit=11&group=true. However, keep in mind that whenever a view is invoked, the indexer will kick in and index any new changes since the last index. Because this is our first invocation of the view, it will index all changes (100K) so it’s going to take some time. This will be the opportunity for us to observe the speed of indexing, so before we invoke that, let’s get our script ready to monitor the speed of the indexing.
Monitor changes-per-second metric
CouchDB exposes its indexing status through the /_active_tasks endpoint. It contains the number of changes to be indexed in total and the number of changes already indexed. From that, we can calculate the changes per second as our benchmark. As stated before, you can find the code here
python cps.py _design/scoresByMonthJS
This starts a monitoring script on the specified design doc, and prints out changes per second number every 1 second.
With this script running, in another terminal, let’s trigger the view:
curl "http://localhost:9999/test/_design/scoresByMonthJS/_view/scoresByMonth?limit=11&group=true"
Go back to the terminal where the monitoring script is run. We will see that it started to print out cps values:
$ python cps.py _design/scoresByMonthJS
design doc: _design/scoresByMonthJS
Press Ctrl+C to exit
c/s = 4141.00
c/s = 7373.00
c/s = 7120.50
c/s = 5378.25
c/s = 5534.80
c/s = 5605.50
c/s = 5670.43
c/s = 5719.12
c/s = 5757.00
c/s = 6060.00
c/s = 6110.50
c/s = 6041.64
c/s = 5570.54
c/s = 5605.50
c/s = 5629.07
c/s = 5649.69
c/s = 5632.24
And when the indexing is complete, press Ctrl+C and the average will be printed out:
^Caverage = 5799.93
and in the other terminal, we will see the result:
$ curl "http://localhost:9999/test/_design/scoresByMonthJS/_view/scoresByMonth?limit=11&group=true"
{"rows":[
{"key":["2015","12"],"value":8241946},
{"key":["2016","01"],"value":20924965},
{"key":["2016","02"],"value":19422002},
{"key":["2016","03"],"value":21217217},
{"key":["2016","04"],"value":20588868},
{"key":["2016","05"],"value":21011332},
{"key":["2016","06"],"value":20404601},
{"key":["2016","07"],"value":20831013},
{"key":["2016","08"],"value":21446896},
{"key":["2016","09"],"value":20340594},
{"key":["2016","10"],"value":20993863}
]}
So the average for a Javascript view is around 5.8k changes per second.
Builtin Reducer
Many of you with CouchDB knowledge will quick to point out that I used a Javascript function as reducer to calculate the sum of the values. This is not very efficient, since (1) data will have to be serialized and sent to the external query server to calculate the result and (2) Javascript isn’t the fastest at mathematics (the default couchjs is using the Spider Monkey engine). We can cut short this loop by using the builtin _sum reducer, which is written in Erlang and run on the same runtime as CouchDB itself, therefore, cut the roundtrip to the query server plus the serialization/deserialization cost.
To use it, simply change the reducer function to _sum. Start the monitoring and trigger indexing.
design doc: _design/scoresByMonthJS
Press Ctrl+C to exit
c/s = 3333.00
c/s = 9696.00
c/s = 11312.00
c/s = 11850.67
c/s = 12069.50
c/s = 12221.00
c/s = 12338.83
c/s = 12365.29
c/s = 11741.25
^Caverage = 10769.73
So, by simply changing the reducer from external to builtin, the indexing speed improved 185.5%!
Benchmark Python views
Map/reduce
We save the following map/reduce function as _design/scoresByMonthPY:
Map:
def map(doc):
if 'metadata' in doc and 'createdAt' in doc['metadata']:
created_at = doc['metadata']['createdAt']
year, month, _ = created_at.split('-')
yield [year, month], doc['score']
Reduce:
def reduce(keys, values, rereduce):
return sum(values)
We use a sub-optimal reducer to draw comparison with the first Javascript benchmark we did before. And it turned out that Python views are slightly more performant:
$ python cps.py _design/scoresByMonthPY
design doc: _design/scoresByMonthPY
Press Ctrl+C to exit
c/s = 2323.00
c/s = 6969.00
c/s = 8433.50
c/s = 8719.67
c/s = 8913.25
c/s = 8948.60
c/s = 8972.17
c/s = 9003.43
c/s = 9014.25
c/s = 9011.44
c/s = 9019.30
^Caverage = 8120.69
Let’s switch the reducer to CouchDB’s builtin _sum function.
design doc: _design/scoresByMonthPY
Press Ctrl+C to exit
c/s = 5959.00
c/s = 8938.50
c/s = 9864.33
c/s = 10403.00
c/s = 11842.25
c/s = 11837.20
c/s = 11833.83
c/s = 11802.57
c/s = 11753.88
^Caverage = 10470.51
The result isn’t that different from Javascript map function with builtin reducer.
Improving couchpy
simplejson
Since an external query server need to deserialize JSON input from CouchDB and serialize the result back into JSON form to be consumed by CouchDB, the implementation of the JSON module could potentially make a difference in performance. As couchpy defaults to use the system json module provided by the Python distribution, it’s not the most performant implementation. simplejson is a drop-in replacement for the Python’s json module which uses a C implementation for json encoding/decoding. Let’s try that.
First, we need to install simplejson (which requires Python C headers to be installed. On Debian, install python-dev package) on the container and then modify the config to use couchpy --json-module=simplejson as the Python query server command.
Let’s see the result:
$ python cps.py _design/scoresByMonthPY
design doc: _design/scoresByMonthPY
Press Ctrl+C to exit
c/s = 5454.00
c/s = 11514.00
c/s = 12019.00
c/s = 12120.00
c/s = 9675.80
c/s = 9999.00
c/s = 10316.43
c/s = 10516.62
^Caverage = 10201.86
Interesting… simplejson performance is only on-par with dthe stock json module. That’s a little unexpected. However, if you look at top while the indexer is running, the Python process never consumes more than 60% of CPU time.
PyPy
We can also try to use pypy as our interpreter. PyPy is an alternative implementation of Python that adds a Just-In-Time compiler. The benchmark showed a marginal improvement over CPython.
$ python cps.py _design/scoresByMonthPY
design doc: _design/scoresByMonthPY
Press Ctrl+C to exit
c/s = 6767.00
c/s = 10453.50
c/s = 11648.67
c/s = 12195.75
c/s = 12524.00
c/s = 13816.80
c/s = 12841.43
^Caverage = 11463.88
The performance for PyPy isn’t much greater is probably due to the fact how the CouchDB query protocol works: it sends the query server one document at a time to run the map function over. JIT excels at loops but at each request/response cycle, the query server only operates one document at a time. The JIT wasn’t given a chance to warmup. That was my conjecture anyway, as I’m not an expert on PyPy’s JIT internals.
Native Views
As we can see, the performance of external query servers don’t vary by a lot. Another interesting observation is that the query server process was not fully saturated, doesn’t matter when it’s Javascript, Python, or PyPy.
Looking at the CouchDB query protocol, it seemed that the process of feeding data to the external query server is the bottleneck: The CouchDB erlang process serializes the document from Erlang to JSON, send JSON to the query server’s process. The query server deserializes JSON, run the map/reduce function and serializes that into JSON to be fed back to the CouchDB process, and the CouchDB process deserializes that back into Erlang’s data structure. Wouldn’t it be great if all of that can happen within the same runtime as the CouchDB process? That brought me to research writing CouchDB views in Erlang, and indeed, there is such a thing.
Having dabbled with Erlang at the beginning of my career, I’m not put off by the idea. However, Erlang is not a beginner-friendly language if you’re coming from the C/C++/Java line.
First we need to enable Erlang native query server in the configs.
curl -XPUT -H "Content-Type:application/json" http://localhost:9999/_config/native_query_servers/erlang -d'"{couch_native_process, start_link, []}"'
Map
It takes some trial-and-error but there it is, the Erlang version of the map function:
fun({Doc})->
case proplists:get_value(<<"metadata">>, Doc) of
{Metadata} ->
CreatedAt = proplists:get_value(<<"createdAt">>, Metadata),
case string:tokens(binary_to_list(CreatedAt), "-") of
[Year, Month|_] -> Emit([list_to_binary(Year), list_to_binary(Month)], proplists:get_value(<<"score">>, Doc))
end
end
end.
CouchDB documents are represented in Erlang as a tuple of lists (proplists), and hence we use proplists:get_value to extract values given certain “keys”. Erlang has great pattern-matching feature so we use it to further extract Year and Month from the split string. Strings in Erlang are represented as a list of binary numbers (referring to their codepoint). <<"createdAt">> is the literal to convert the string createdAt to its binary list equivalent to match the type of the document object. Again, I’m not an Erlang expert, so please point out my inaccuracies with regard to the language.
Reduce
We will use the same reducer _sum as it has served us well.
Benchmark
$ python cps.py _design/scoresByMonthERL
design doc: _design/scoresByMonthERL
Press Ctrl+C to exit
c/s = 19821.25
^Caverage = 19821.25
There you have it! The Erlang view is about 173% as fast as the previous fastest (PyPy) option.
One caveat about using Erlang native views: since it’s running on the same runtime as CouchDB and is not sandboxed, it’s able to access CouchDB’s internal API and call Erlang functions that maybe destructive. Do not run untrusted view functions directly.
Let’s look at where we stand in terms of indexer option and performance:
| Option | Average c/s |
|------------------------------------|-------------|
| couchjs/external reducer | 5799.93 |
| couchjs/builtin reducer | 10769.73 |
| couchpy/external reducer | 8120.69 |
| couchpy/builtin reducer | 10470.51 |
| couchpy/simplejson/builtin reducer | 10201.86 |
| couchpy/pypy/builtin reducer | 11463.88 |
| erlang native view | 19821.25 |
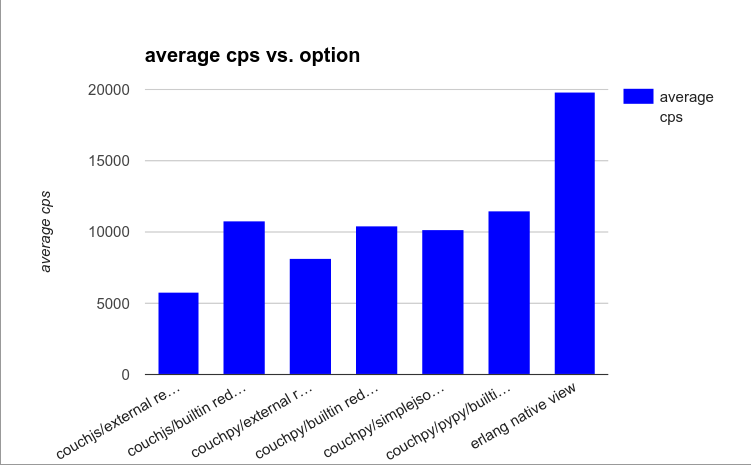
Benchmark
Benchmark with bigger documents
The above set of tests are done on documents with smallish size. Let’s add some junk data to the documents. I modified the document generation procedure to add in some arbitrary string properties so now the average document size is about 300k.
def generate_doc(i):
doc = {
'metadata': {
'docType': 'score',
'createdAt': random_date()
},
'username': random_str(),
'score': random.randint(0, 5000),
'custom_data': {
}
}
for _ in range(random.randint(0, 100)):
doc['custom_data'][random_str()] = \
base64.b64encode((random_str() * 100).encode('ascii')).decode('ascii')
with this new database, rerun the above benchmark. We have:
| Option | Average c/s |
|------------------------------------|-------------|
| couchjs/external reducer | 648.50 |
| couchjs/builtin reducer | 727.18 |
| couchpy/external reducer | 1564.38 |
| couchpy/builtin reducer | 1590.20 |
| couchpy/simplejson/builtin reducer | 2352.69 |
| couchpy/pypy/builtin reducer | 1265.20 |
| erlang native view | 9363.44 |
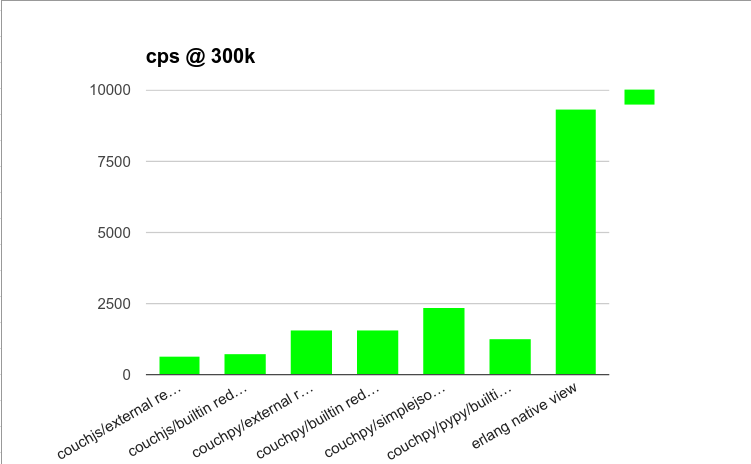
Benchmark @ 300k
Result Comparison
Let’s combine the two tables together:
| Option | cps@1k | cps@300k |
|------------------------------------|-------------|-------------|
| couchjs/external reducer | 5799.93 | 648.50 |
| couchjs/builtin reducer | 10769.73 | 727.18 |
| couchpy/external reducer | 8120.69 | 1564.38 |
| couchpy/builtin reducer | 10470.51 | 1590.20 |
| couchpy/simplejson/builtin reducer | 10201.86 | 2352.69 |
| couchpy/pypy/builtin reducer | 11463.88 | 1265.20 |
| erlang native view | 19821.25 | 9363.44 |
Here are some conclusions we can draw from this experiment:
- Native Erlang views are the fastest by a large margin.
- Native Erlang views’ advantage is even more obvious when having large documents
- Avoid external reducer as much as you can. (i.e., Use the builtin reducer whenever you can)
- PyPy does not offer performance improvements for Python views (in some cases, it’s even worse) probably due to the way query protocol works
- Javascript view performance isn’t great out-of-the-box. Maybe SpiderMonkey can be replaced by NodeJS?
- Use simplejson for Python view when documents are larger