Use rabbitmq DLX to implement delayed retry
30/Apr 2015
In this post, I’m going to describe the experience at $DAYJOB regarding implementing delayed retry using rabbitmq’s DLX combined with a TTL. The technique has been described at a few places but it is new to me personally and our company. I’d like to capture the experience we had both in implementing and in deploying to production.
The problem
At $DAYJOB we have a service that integrates with a 3rd-party API that processes credit card payments and when successful, records a payment object on our customer’s invoices, and change the invoice status. Pretty straight-forward stuff. However, lately we’ve been experiencing an elevated amount of random failures from our service provider.
Calls to our provider to create a checkout using the client’s credit card information would time out randomly, or return an “unknown error”. When it happens, we don’t record a payment object on the invoice since we don’t know the actual status of the checkout, nor do we have the reference_id for the checkout. However, as we discovered, some of these timed-out calls did go through and the clients’ credit cards charged.
We checked with our service provider and were told that they have been experiencing increased volumes and their infrastructure currently can’t keep up. However, they suggest that we use an undocumented feature which allows a unique_id to be passed in along with the checkout call. The unique_id serves as an idempotent key (similar to Stripe’s). Multiple calls with the same unique_id won’t create multiple checkout objects on their end and thus ensuring the checkout is made but won’t double/triple charge the customer’s car.
Architecting the solution
Armed with this new secret API feature, our team goes back to the drawing board. At work, we use rabbitmq extensively for asynchronous processing. If some operation doesn’t have to be carried out synchronously with a web request, we throw a message on the queue and have a queue consumer process that message and update states. We use a library called sparkplug that makes writing queue consumer super-easy. So, everything seems to fall in friendly terrotiries: we make a checkout call with a random id and when we encounter timeout or unknown error, instead of returning an error response to the user, we return 202 Accepted to our user and throw a message on the queue, so a consumer can grab it and retry the checkout with the same original unique_id.
The missing piece
However, we quickly realized it’s not that simple. What if the retry encountered the same error? We can put it back on the queue, but when does it get processed by the consumer again? We want to add a time delay to the subsequent retries, and the orginal retry as well.
Dead-Letter-Exchange and TTL
After some research on the internet, seems like this problem has been solved before.
The idea here is that you have two queues: Qa and Qb. When a checkout request times out, we put a message on a Qa. Qa is declared with x-dead-letter-exchange, x-dead-letter-routing-key and x-message-ttl (in milliseconds). When the message is in Qa for ttl milliseconds, the message will be re-routed to the specified dead-letter-exchange with the routing key. We can bind Qb to the exchange with the routing key, and attach a consumer to only Qb and retry the checkout call.
If the retry call fails for the same reason (timeout or unknown error), we re-publish the message to Qa again and acknowledges the message so it’s no longer in Qb.
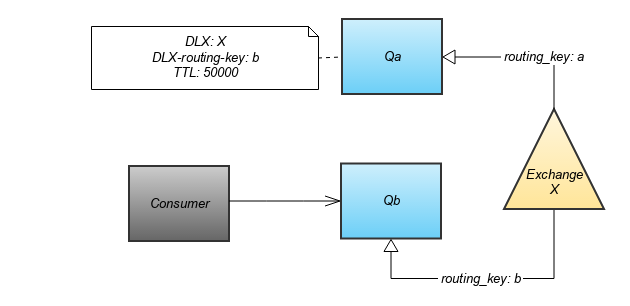
Flow diagram
The whole flow looks like this:
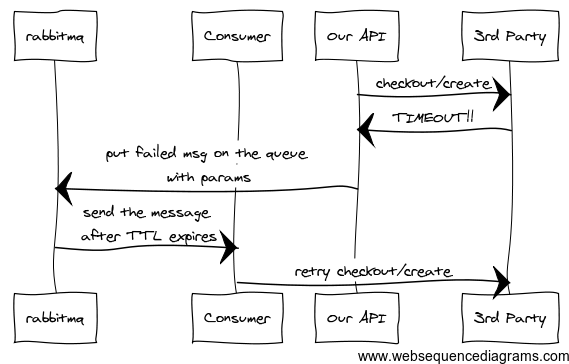
Flow diagram
Implementation, Testing Strategy and Deployment saga
Implementation
Implementation is probably the most straight-forward phase of the project once we have the design on paper. The only obstacle is that the library we use for writing rabbitmq consumers (sparkplug) does not support declaring queues with extra parameters, and the DLX related parameters: x-dead-letter-exchange x-dead-letter-routing-key, and x-message-ttl are all “extra parameters” according to amqplib, which is used by sparkplug. To solve this, I sent this PR to sparkplug, so it recognizes extra parameters and pass them down to amqp library.
Another road block appeared when we ran the system on our dev images for the first time. The underlying amqplib would error out on startup. Upon closer investigation, it appeared the error happened while talking to rabbitmq and the amqplib can’t handle certain rabbitmq frames. So I went searching for the amqp project, only to find out that it was deprecated long ago. Fortunately, there’s a fork of the library amqp that’s maintained by the reputable Celery project. It’s has API compatibility with amqplib and appeared to be a drop-in replacement. We dropped it in and everything seems to work. Reading the online literature, it seems to be the case that the old library does not handle the TTL amqp extension.
Testing Strategy
So, since the 3rd party API timeout is an edge case, they did not provide a way trigger this behaviour the same way we can trigger, say, a declined transaction. We could fake the URL for the 3rd party service in DNS or /etc/hosts or we can change the SDK to change the base url for their API to somewhere else and cause a timeout that way, but neither is ideal. The biggest disadvantage is that we have no way of getting a request out of the retry state.
Eventually, we decided to MITM ourselves :) We can write a simple proxy server, and for the most part, it’s going to be a pass-through, but on certain requests, we intercept it and return an unknown error (500 series with specific response body). To trigger it, we set the checkout amount to $666, and in the proxy, we keep an internal counter based on the checkout’s unique id, and increment the counter every time it’s retried, and then we can set a max retry threshold in the proxy so the proxy becomes a pass through again if the max retry threshold is reached.
We used this small nifty library pymiproxy as a base for our proxy server. It turns out the proxy is pretty straight-forward as well, and a big shout-out to the author of pymiproxy.
Deployment
Everything until now is like a cake walk. Sure, there are some problems with the underlying libraries but that requires patching but they were quite easy to identify and fix. Deployment, on the other hand, has been like riding on the Behemoth in Canada’s Wonderland.
First of all, while getting the code onto the testing environment, we encountered the first gremlin. The staging is running on the exact same version of rabbitmq and the exact same configuration. However, on staging, when a message is published on the DLQ (Qa) in our example, after TTL, the message would simply disappear and did not get routed to Qb. What’s worse, sometimes even Qa is completely gone after the message is dropped on the floor! This is terribly frustrating. The queue is declared as durable, and so is the exchange. I even did a side-by-side comparison of the sparkplug log output to see if anything is different. Well, there was! The declaration sequence is different between staging and dev. On dev, the dead-letter exchange is declared before Qa which specifies x-dead-letter-exchange. That makes sense! Reading the sparkplug code, it calculates the dependencies between queues, exchanges, bindings and consumers to determine the order of which they should be declared. However, our modification that enabled sparkplug to pass down DLX, but sparkplug has no idea that the queue depends on the DLX! Based on this observation, I cooked up another PR such that if DLX is specified, make sure we make the DLX a dependency of the queue so the exchange gets declared before it. Did a few tests locally, and hey, it appears to be working!
Just as I thought my shrewed observation has solved this major mystery, the second day, people reported that the queue started go AWOL again! Grumbled, I sat down and read carefully the documentation on dead-letter exchange and discovered this:
Note that the exchange does not have to be declared when the queue is declared, but it should exist by the time messages need to be dead-lettered; if it is missing then, the messages will be silently dropped.
This invalidates my previous hypothesis that the out-of order declaration was the root cause of the problem. There we go, I was back to square one.
At this time, I wanted to try a different approach. Instead of forming hypothesis from observation, I searched for evidence. I went on the server, and start to look at the logs to search for any traces that can be salvaged. The rabbitmq log is very noisy with all the connection messages. Once in a while you get something remotely interesting, but they were not relevant. Then I manually published a message on the queue, and waited for the message and queue to disappear. Lo and behold, there’s something in the logs!
There’s our smoking gun! Further gooling revealed this. That’s EXACTLY our issue! And the version of rabbitmq we’re using is EXACTLY 2.8.1! What a relief! We just need to upgrade to 2.8.2 and everything would be fine.
So there I was, preparing an internal repository to host the rpm (since we’re on a hopelessly old version of CentOS), and prepared puppet changes for the new version. Deployed on all the environments and sent it off to QA. QA ok’ed it just before the weekend and life is good again.
Except, not at all! There are a few more surprises waiting for us before the end of tunnel. First of all, our partner whose payment API we’re integrating has received an imminent DDOS threat, and fearing not having a retry mechanism would caused a huge burden for us and our support crew, we need to get this out to production ASAP. After pulling some levers and convincing our ops team that this is a relatively low risk point release upgrade (from rabbitmq 2.8.1 to 2.8.2), we got the green light and ops are on their way upgrading rabbitmq. Everything seemed to be going alone well, until, when we switched all components to point to the hosts that’s on the new rabbitmq, our app stopped working! Phone calls flooded in, alerts set off everywhere and on top of that, even the streets in front of our building had a couple of emergency vehicles passing by! Goodness, what have we done! Ops quickly rolled it back, and we were left dumbfounded by this yet another surprise.
Analyzing the logs from various components during the downtime, it appeared the components talking to rabbitmq have timed out trying to publish messages. We checked that the hosts can indeed reach each other, all the names can be resolved and firewall rules are not in effect. So, we hit a wall again.
On the second day, we regrouped, and experimented on the backup data centre. We upgraded, and tried to put a message on the queue, and guess what, it blocked! It’s great that we reproduced the issue. Since the staging environment worked just fine, I captured strace on the staging environment, and ops did the same on prod, and compared the output. It’s pretty clear that the process was waiting on reading socket (syscall was recvfrom(...)) and it blocked. Then I did tcpdump and compared that with the output on prod, and also proven to be futile.
In that afternoon, our fortune suddenly took a positive turn, when one of the ops discovered this in the logs while starting the new rabbitmq:
=INFO REPORT==== 29-Apr-2015::14:51:09 ===
Disk free space limit now exceeded. Free bytes:19033128960 Limit:50634379264
So, this version of rabbitmq started to check free disk space, and blocks incoming message if the disk space is deemed inadequate! Wow, this is so unexpected that we all laughed when we discovered this to be the root cause. However, for me, I need to be convinced that why it wasn’t an issue for staging environment.
So I cloned rabbitmq git repository, and looked for anything that’s related to disk_free_limit. Finally, I found this:
{disk_free_limit, {mem_relative, 1.0}},
from here. Since we’re using the default config, this is in effect, and it essentially says “stop accepting message if the disk space is not at least as big as the RAM”, and it just so happens on prod, we have 50G of RAM and therefore, require at least 50G of free space for rabbitmq to start accepting messages!
Reading the rabbitmq 2.8.2 release notes, and they did mention this “feature”, but failed to mention that it could block your connection forever and bring your site down…
Conclusion
There you go. That’s our adventure implementing and deploying delayed retry using rabbitmq’s DLX and TTL. It’s frustrating and rewarding at the same time, and there’s definitely something we can all take home with:
- Software is hard, even for experienced developers and ops
- Gather all the evidences before forming hypothesis on the root cause
- Certainly, read the docs thoroughly before hypothesizing
- Expect problems when switching environments
I haven’t been blogging for a while, partly because life catches up, and partly because I’ve been less than disciplined but I spent some time writing down this experience worth remembering :)